The ozbabynames package provides the data object `ozbabynames` containing popular Australian baby names by sex, state/territory and year. The coverage is very uneven, with some states only providing very recent data, and some states only providing the top 50 or 100 names. The ACT do not provide counts, and so no ACT data are included. South Australia has by far the best data, with full coverage of all names from 1944-2017 and 2024, although only the top 100 names in other years.
Examples
head(ozbabynames)
#> # A tibble: 6 × 5
#> year state sex name count
#> <int> <chr> <chr> <chr> <int>
#> 1 2024 New South Wales Female Charlotte 383
#> 2 2024 New South Wales Female Amelia 367
#> 3 2024 New South Wales Female Olivia 316
#> 4 2024 New South Wales Female Mia 308
#> 5 2024 New South Wales Female Isla 298
#> 6 2024 New South Wales Female Chloe 275
# Plot most popular names in 2016
library(ggplot2)
library(dplyr)
#>
#> Attaching package: ‘dplyr’
#> The following objects are masked from ‘package:stats’:
#>
#> filter, lag
#> The following objects are masked from ‘package:base’:
#>
#> intersect, setdiff, setequal, union
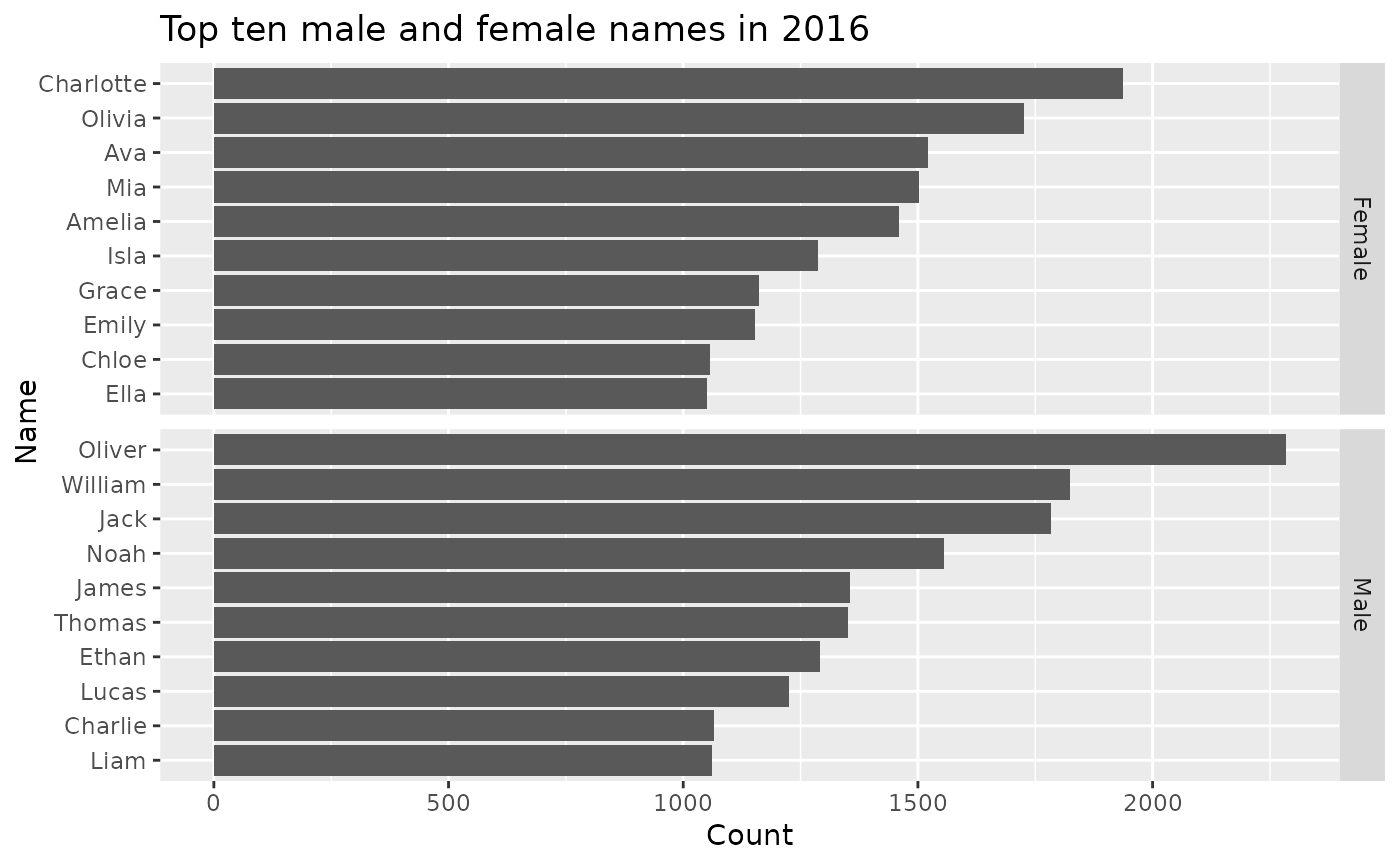
ozbabynames |>
filter(year == 2016) |>
group_by(sex, name) |>
summarise(count = sum(count)) |>
arrange(-count) |>
top_n(10) |>
ungroup() |>
ggplot(aes(x = reorder(name, count), y = count, group = sex)) +
geom_bar(stat = "identity") +
facet_grid(sex ~ ., scales = "free_y") +
coord_flip() +
ylab("Count") +
xlab("Name") +
ggtitle("Top ten male and female names in 2016")
#> `summarise()` has grouped output by 'sex'. You can override using the `.groups`
#> argument.
#> Selecting by count